-
Kafka 심화 개념 - 4데엔 공부 2024. 12. 15. 11:27
4-1. Apache Kafka Connecting
System 간 메시지 전송할 때 잘 만들어진 Kafka Connector 사용
Kafka Connect란
> Apache Kafka 안팎으로 데이터를 스트리밍하기 위한 Framework
Connector: Task를 관리하여 데이터 스트리밍을 조정하는 Plugin(jar), Java Class/Instance
Tasks: Kafka와 다른 시스템간의 데이터를 전송하는 방법의 구현체(Java Class/Instance)
Workers: Connector 및 Task를 실행하는 실행 중인 프로세스(Process)

> Worker 프로세스가 Connect, Task 관리
Converter: Connect와 데이터를 보내거나 받는 시스템 간에 데이터를 변환하는데 사용되는 Components(Java Class)
Transforms: Connector에 의해 생성되거나 Connector로 전송되는 각 메시지를 변경하는 간단한 Components(Java Class)
Dead Letter Queue: Connect에서 Connector 오류를 처리하는 방법
Standalone(Single Process) vs Distributed Workers(Multi Process)

Multiple Distributed Connect Clusters

> group.id로 Cluster간 구분
4-2. Single Message Transform(SMT), Converter
Connect Worker: Connector를 배포/구동시키는 프로세스
> Connect Class 지정
> Connect Worker에 Connector Instance 및 Task 생성
: Connect Task가 Source 시스템에서 데이터 가져와 Connect Record로 변환
> Key와 Value를 Byte Array로 변환하기 위해 각각 Converter 설정
> Converter는 Connect Record를 Byte Array로 변환 후 Kafka로 전달
Single Message Transform(SMT)
> 단건 메시지별 데이터 변환 가능

> Task와 Converter 사이에서 데이터 변환 필요한 경우 사용
SMT 설정: Chaining 가능
> 여러 개의 SMT를 연결(Chaining)하여 사용 가능

> 단건 메시지 별 데이터 변환 기능
Sink Connector의 Data Flow
> Source Connector의 역방향 순서

5. Confluent Schema Registry
Schema: Data Structure, 데이터의 구조
> 데이터를 만들어내는 Producer와 데이터를 사용하는 Consumer간의 계약으로 사용
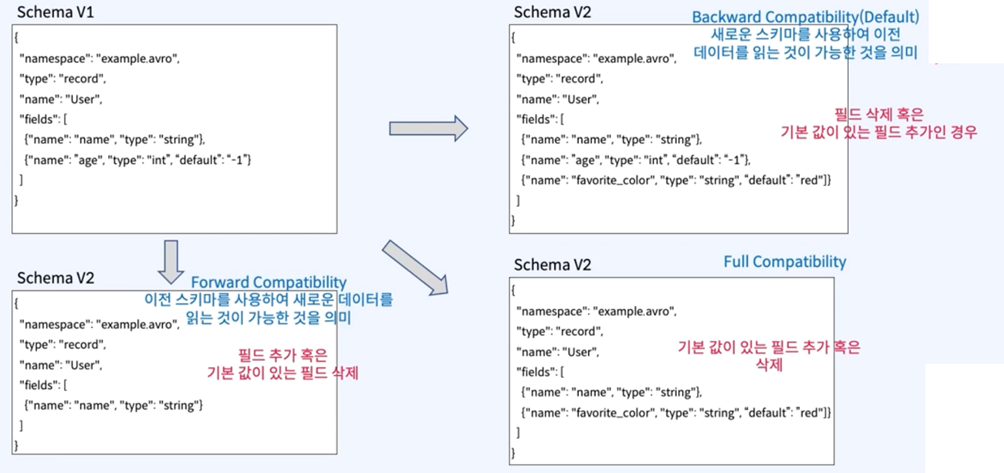
Schema Evolution
> 비즈니스 변경 등 스키마 진화
AVRO: Data Serialization System
> 데이터를 serialization 제공(직렬화)
> 바이너리이므로 데이터 효율적 저장
> Java 포함많은 프로그래밍 언어 지원
AVRO 장단점

Schema Evolution - Compatibility(호환성)
Schema 설계 고려점
> 삭제 가능성 있는 필드는 Default Value 반드시 지정
> 추가되는 필드 Default Value 지정
> 필드명 변경하지 않음
Confluent Schema Registry: 스키마저장소
> 스키마의 중앙 집중식 관리 제공
> 모든 스키마 버전 기록 저장
> Avro 스키마 저장과 검색을위한 RESTful 인터페이스 제공
> 호환성설정에 따라 스키마 진화 가능
각 메시지와 함께 Avro 스키마 보내는 것 비효율적
> 대신 Avro 스키마를 나타내는 Global Unique ID가 각 메시지와 함께 전송
Schema Registry는 특별한 Kafka Topic에 스키마 정보저장
> “_schemas” Topic
> kafkastore.topic 파라미터로 변경가능
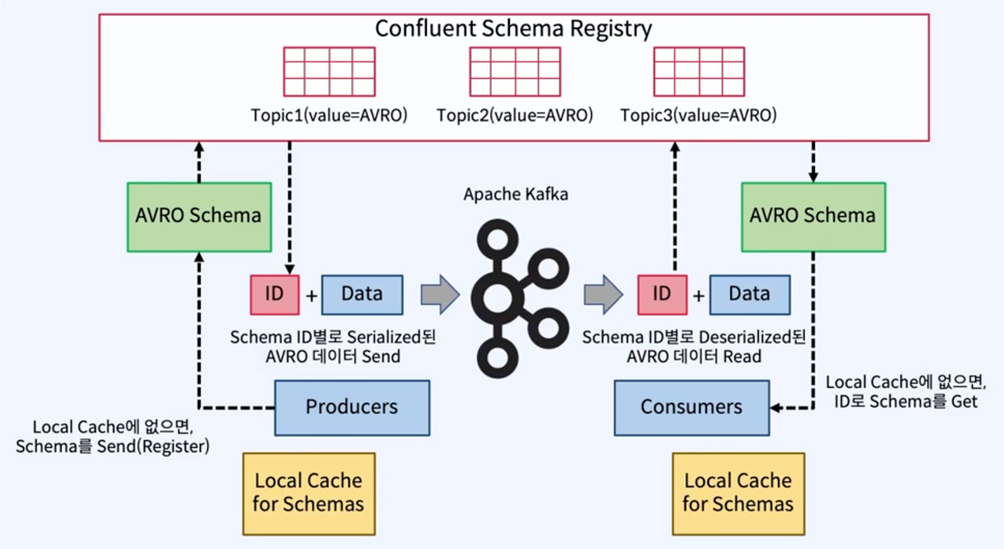
Schema 등록 및 Data Flow
> Producer와 Consumer는 Local Cache 사용
6. Kafka Streams, ksqlDB
Realtime Event Stream Processing
> 실시간 이벤트 스트림 데이터 분석 및 처리
> Database에 저장 후 분석 및 처리하는게 아니라, kafka의 데이터를 바로 처리
기존에는 Apache Spark(분산 클러스터 컴퓨팅 프레임워크) /
Storm(분산형 스트림 프로세싱 프레임워크) / Flink(통합 스트림 처리 및 배치 처리 프레임워크) 사용했음
Kafka Streams
> Event Streaming용 Library(Java, Scala)
> Framework가 아니라 별도 Cluter 구축 필요 없음
> application.id로 KStreams Application을 grouping
> kafka 0.10.0.0에서 처음 포함됨
ksqlDB
> Event Streaming Database(SQL엔진) - RDBMS/NoSQL DB 아님
> 간단한 Cluster 구축가능 - 동일 sql.service.id로 여러 DB 기동

> SQL 유사한 형태로 ksqlDB에 명령어 전송하여 수행


Data Flow

개발방식 및 배포 방식 차이
'데엔 공부' 카테고리의 다른 글
Kafka 심화 개념 - 3 (2) 2024.12.14 Kafka 심화 개념 - 2 (0) 2024.12.13 Kafka 심화개념 - 1 (2) 2024.11.27 Apache Kafka 개념 정리 (2) 2024.11.25